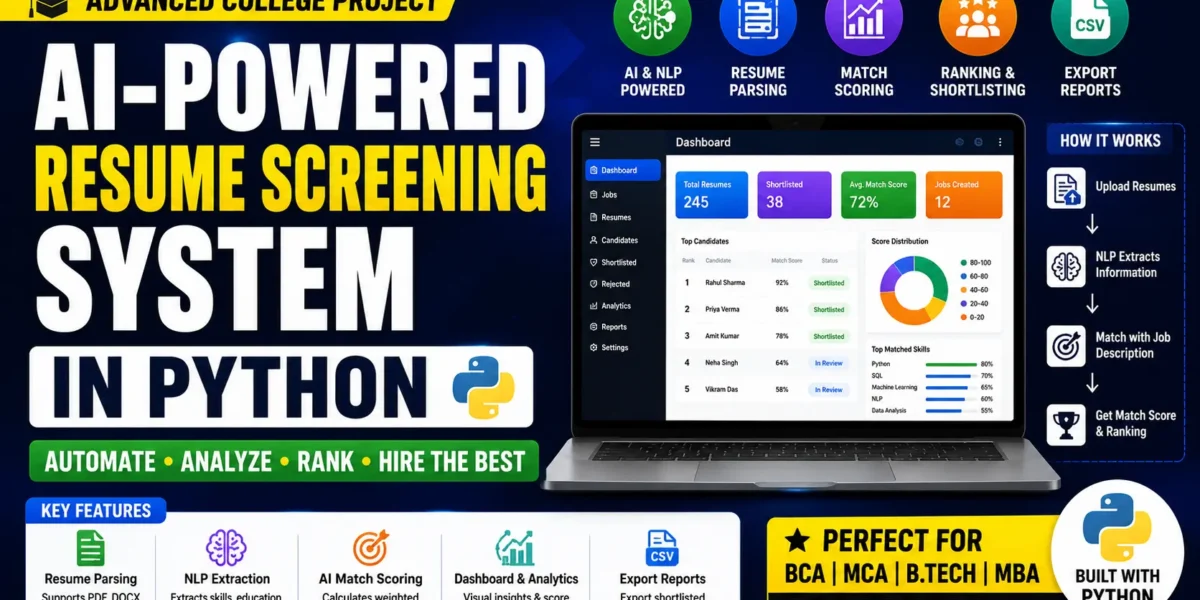
Looking for an AI Powered Resume Screening System in Python with full source code? This is one of the most impressive final year projects for MCA, BCA, B.Tech, and MBA students in 2026, targeting AI, Data Science, and HR-Tech roles. The system screens multiple resumes against a job description, extracts structured candidate information using NLP, and ranks every applicant by a weighted Job-Match Score percentage – complete with an interactive analytics dashboard, skill-gap charts, one-click shortlist or reject actions, and CSV/Excel export. In this post you get the complete source code, full feature breakdown, project structure, tech stack, and step-by-step setup guide.
Table of Contents
Project Overview
| Project Name | AI Powered Resume Screening System with Job Match Score |
| Language Used | Python 3.x |
| Web Framework | Flask (application-factory pattern) |
| ORM | SQLAlchemy |
| AI / NLP | spaCy NER, scikit-learn TF-IDF, optional BERT (sentence-transformers) |
| File Parsing | PyMuPDF (fitz), python-docx |
| Frontend | HTML5, custom CSS design system, JavaScript, Chart.js |
| Database | SQLite (default) / MySQL (switchable) |
| Project Type | Web Application (HR-Tech / AI) |
| Difficulty | Advanced |
| Best For | MCA, BCA, B.Tech, MBA Final Year Students |
| Developer | Updategadh |
About the Project
The AI Powered Resume Screening System is a full-stack HR automation tool built with Flask, spaCy, and scikit-learn that solves a real-world business problem – manually screening hundreds of resumes for a single job opening. Recruiters upload multiple resumes in PDF or DOCX format, define a job description with required skills, minimum experience, and education level, and the system parses every resume, extracts structured candidate information, and ranks applicants by a weighted Job-Match Score percentage.
Unlike a basic keyword-matching tool, this project uses TF-IDF and cosine similarity for semantic resume matching, with an optional BERT engine for deeper contextual understanding. The result is an enterprise-grade HR-Tech project that combines NLP, machine learning, document parsing, REST APIs, and data visualisation in a single polished web application – exactly the kind of project that gets noticed in viva, interviews, and on a fresher resume.
Key Features
- Resume Parser: Extracts clean text from messy multi-format PDF and DOCX resumes using PyMuPDF and python-docx.
- NLP Extractor: Pulls out candidate name, email, phone, skills, education, and experience using spaCy Named Entity Recognition combined with regex patterns.
- Job Description Module: Create jobs with required skills, minimum years of experience, and education level – skills are auto-detected from the JD text.
- Weighted Match Engine: Scores every candidate across skills, experience, education, and semantic similarity using TF-IDF or optional BERT cosine similarity.
- Interactive Analytics Dashboard: Chart.js bar graphs, score distribution doughnut charts, and detailed skill-gap analysis per candidate.
- One-Click Shortlist / Reject: AJAX-powered status updates with live filtering of candidates.
- CSV and Excel Export: Download ranked or shortlisted candidates as CSV or Excel files using openpyxl.
- Pluggable Database: Works out of the box with SQLite, switches to MySQL with a single environment variable change.
- Configurable Score Weights: Adjust the weighting formula directly in the config file without touching core code.
- Unit Tested: Comes with pytest test cases for the core matching engine.
Technologies Used
| Layer | Technology |
| Backend | Python 3, Flask (application-factory pattern) |
| ORM | SQLAlchemy + Flask-Migrate |
| NLP | spaCy (en_core_web_sm) with NER |
| Machine Learning | scikit-learn TF-IDF, optional sentence-transformers BERT |
| Document Parsing | PyMuPDF (fitz), python-docx |
| Frontend | HTML5, custom CSS design system, JavaScript, Chart.js |
| Export | openpyxl (Excel), built-in csv module |
| Database | SQLite (default), MySQL (production-ready) |
| Testing | pytest |
How the Job Match Score Is Calculated
The overall match score is a weighted blend of four signals (all weights are configurable in app/config.py):
match_score = 0.50 * skills
+ 0.20 * experience
+ 0.15 * education
+ 0.15 * semantic_similarity
- Skills (50%): Overlap between required skills from the JD and skills extracted from the resume.
- Experience (20%): Candidate’s years of experience compared to the minimum required (capped at 100%).
- Education (15%): Candidate’s education level ranked against the required level.
- Semantic Similarity (15%): TF-IDF or BERT cosine similarity of the full resume text against the full job description text.
This blended approach makes the system significantly smarter than a plain keyword search – it understands contextual similarity, not just exact word matches.
Related Project
How to Run This Project
Step 1: Enter the Project Folder
cd Ai Powered-Resume-Analyzer
Step 2: Create a Virtual Environment
# Windows
python -m venv venv
venv\Scripts\activate
# macOS / Linux
python -m venv venv
source venv/bin/activateStep 3: Install Dependencies
pip install -r requirements.txtStep 4: Download the spaCy English Model (Recommended)
python -m spacy download en_core_web_smThe app still works without it – the NLP module falls back to regex-based extraction automatically.
Step 5: Configure Environment Variables
# Windows
copy .env.example .env
# macOS / Linux
cp .env.example .envEdit the .env file if you want to use MySQL or enable the BERT engine.
Step 6: Seed Sample Data (Optional)
python seed.pyStep 7: Run the Application
python run.pyConfiguration
All settings live in the .env file (see .env.example):
| Variable | Default | Description |
DATABASE_URL | sqlite:///resume_screening.db | SQLite or mysql+pymysql connection string |
MATCH_ENGINE | tfidf | tfidf (fast, offline) or bert (semantic) |
SECRET_KEY | dev key | Flask session secret |
MAX_CONTENT_LENGTH_MB | 16 | Maximum upload size in megabytes |
Switching to MySQL
- Create the database:
CREATE DATABASE resume_screening; - Set
DATABASE_URL=mysql+pymysql://root:password@localhost:3306/resume_screening - Restart the app – tables are created automatically.
Enabling BERT Semantic Matching
- Uncomment
sentence-transformersinrequirements.txtand reinstall. - Set
MATCH_ENGINE=bertin.env.
Demo Video
Watch the complete walkthrough of the AI-Powered Resume Screening System below, covering resume upload, NLP extraction, match score calculation, the analytics dashboard, and CSV/Excel export:
Screenshots
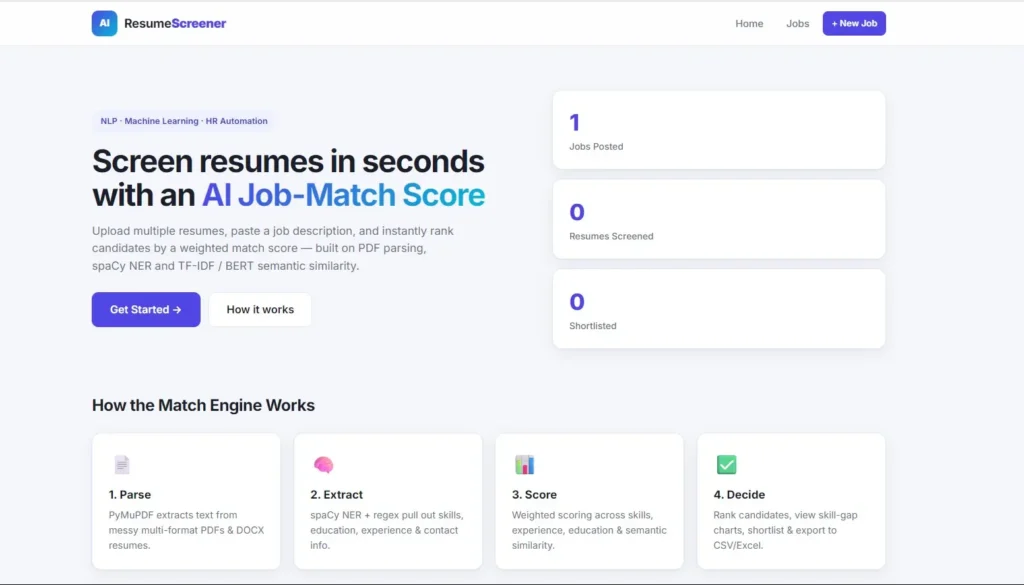
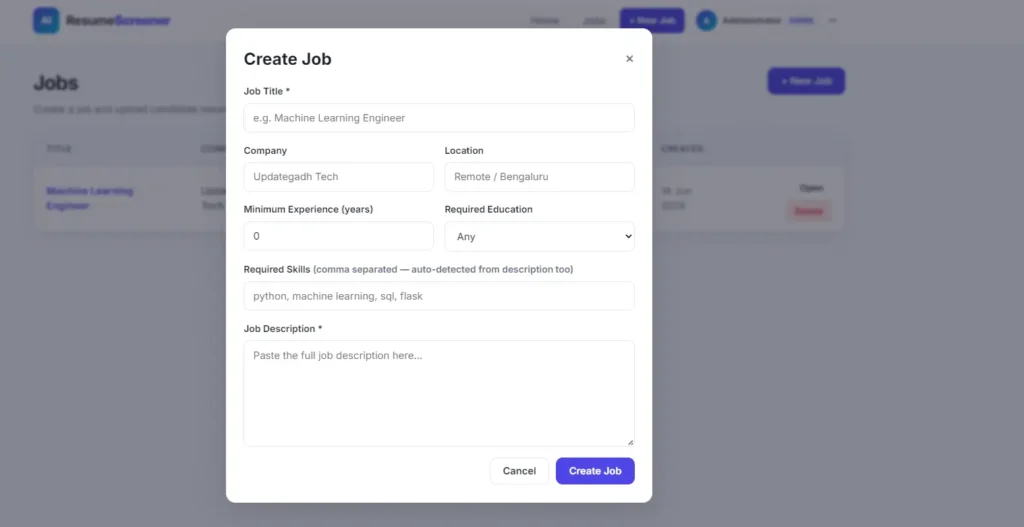
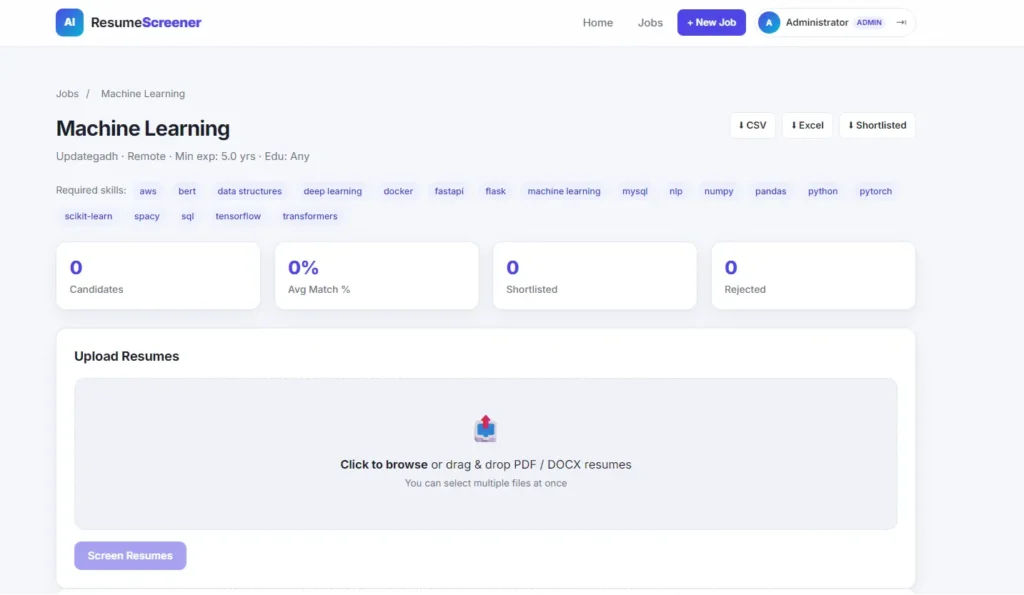
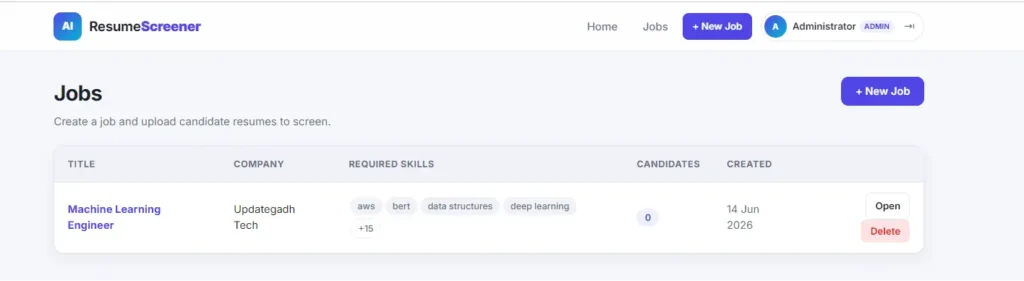
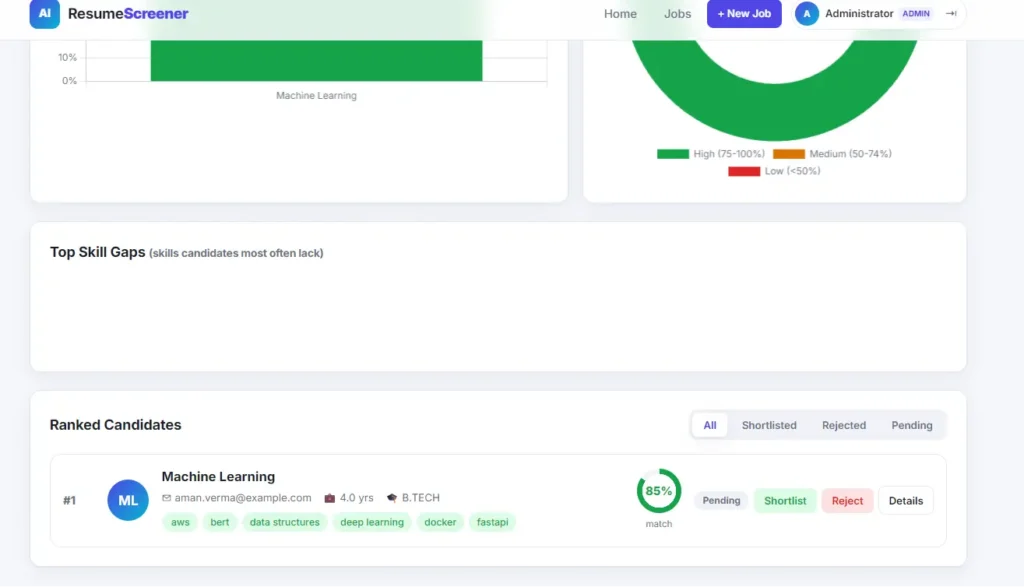
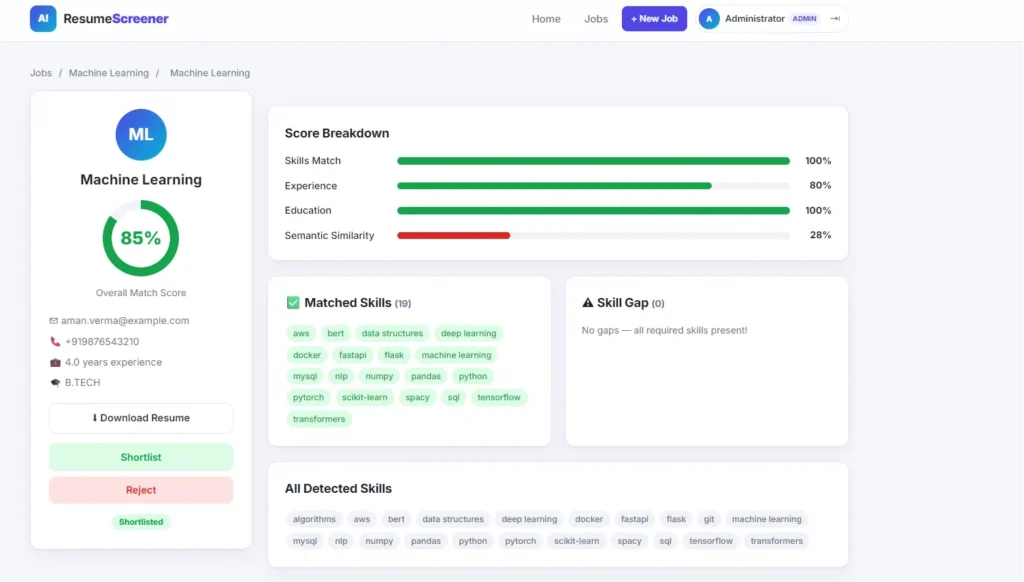
Why This Is a Great Final Year Project
- Real-world HR automation – solves an actual business problem, not a toy use case.
- Combines NLP + Machine Learning + Web Development – covers three trending domains in one project.
- spaCy NER and TF-IDF cosine similarity – directly relevant to AI and Data Science placements.
- Optional BERT integration – shows you understand modern transformer-based NLP.
- Production-grade architecture – Flask application factory, SQLAlchemy ORM, service layer, REST API, unit tests.
- Interactive Chart.js dashboard – visual analytics impress every viva examiner.
- Pluggable database – demonstrates understanding of environment-based configuration.
- Easy to extend – add email notifications, admin login, or deploy to Render or Railway in a day.
How to Download This Project
The complete AI Powered Resume Screening System in Python package includes:
- Full Flask source code with application-factory pattern
- NLP extractor, match engine, PDF parser, and exporter services
- All Jinja2 templates, custom CSS design system, and Chart.js dashboards
- Sample resumes and job descriptions for testing
- pytest unit tests for the core matching engine
.env.exampleand seed script- Project report, synopsis, and PPT for academic submission
For instant support, message us on WhatsApp: +91 79834 34684
Watch Free Video Tutorials on YouTube
Subscribe to DecodeIT2 for daily Python project tutorials, AI walkthroughs, and final year project guides – all free.
Subscribe to DecodeIT2 on YouTube
Frequently Asked Questions (FAQ)
What is an AI Powered Resume Screening System?
It is an HR automation tool that automatically reads multiple resumes, extracts candidate details using NLP, and ranks each candidate against a job description using a weighted match score. It replaces hours of manual screening with a few seconds of automated analysis.
Which technologies are used in this Resume Screening project?
The project uses Python 3, Flask, SQLAlchemy, spaCy for NLP, scikit-learn for TF-IDF and cosine similarity, PyMuPDF and python-docx for document parsing, Chart.js for the dashboard, and openpyxl for Excel export.
Does this project use real machine learning or just keyword matching?
Both. The match engine combines exact skill overlap with TF-IDF cosine similarity, and optionally a BERT semantic model via sentence-transformers, so it captures contextual similarity instead of relying on keyword matches alone.
Is this project suitable for MCA, BCA, B.Tech, and MBA final year submission?
Yes. It is an advanced-level project that covers AI, NLP, machine learning, web development, and HR-Tech – making it equally strong for technical (MCA, BCA, B.Tech) and management (MBA HR / IT) submissions.
Can this system handle PDF and Word resumes?
Yes. PyMuPDF handles PDF resumes and python-docx handles DOCX files. The parser is built to deal with multi-column layouts and messy formatting commonly found in real resumes.
Can I switch the database from SQLite to MySQL?
Yes. Change the
DATABASE_URLvariable in the.envfile to a MySQL connection string and restart the app – tables are created automatically by SQLAlchemy.Does this project include a report, PPT, and synopsis?
Yes. The download package includes the complete source code along with the project report, synopsis, and PPT ready for academic submission.
AI Powered Resume Screening system in python with source code
ai powered resume screening system in python github
ai powered resume screening system in python pdf
ai based resume-screening system project github
ai powered resume screening system project
ai based resume screening system project with source code
ai powered resume screening system research paper
resume screening using machine learning github


[…] AI-Powered Resume Screening System in Python […]
[…] AI-Powered Resume Screening System in Python […]