
Fake news spreads faster than real news — and that is a serious problem in today’s digital world. Social media, blogs, and messaging apps allow anyone to share information in seconds, but not all of it is true. This is exactly why a Fake News Detection System using Machine Learning and NLP is one of the most relevant and impressive projects you can build as a CS/IT student in 2026. It combines Python, TF-IDF, SVM, DistilBERT, and a Streamlit web interface into one complete solution that solves a real-world problem — making it a project that stands out in every placement interview and viva.
Fake News Detection System Using Machine Learning Project with Source
Also Explore on UpdateGadh:
Project Overview
| Project Name | Fake News Detection System |
| Language | Python 3.8+ |
| Technology | Machine Learning, NLP, Deep Learning |
| Models Used | Logistic Regression, Linear SVM, DistilBERT |
| Text Features | TF-IDF Vectorization |
| Frontend | Streamlit |
| Dataset | Labelled Real and Fake News Articles (balanced) |
| Difficulty | Intermediate to Advanced |
| Best For | BCA, MCA, B.Tech CS/IT Final Year Students Globally |
Key Features
- Three ML models in one project — Logistic Regression, Linear SVM, and DistilBERT all trained and deployed side by side, letting students compare performance across classical ML and Deep Learning approaches
- Single article prediction — paste any news article text and get an instant REAL or FAKE prediction with a confidence score from any of the three models
- Batch CSV upload — upload a CSV file of multiple articles for bulk analysis, making it easy to demo large-scale detection during viva
- Model comparison dashboard — compare predictions from Logistic Regression, SVM, and BERT side by side on the same article to understand how different approaches handle the same text
- Download prediction results — export bulk analysis results as a CSV file for documentation and project reports
- Clean Streamlit web interface — fully built in Python with no HTML or CSS required; shows students how to deploy an ML model as a working web application
- Balanced real-world dataset — trained on labelled real news from trusted sources and fake news from flagged websites with equal class distribution to avoid biased predictions
🎬 Watch the Full Project Tutorial on YouTube!
We’ve built this project step by step on our YouTube channel. Watch the full video, like, and subscribe for daily project tutorials.
Technologies Used
| Layer | Technology | Purpose |
|---|---|---|
| Language | Python 3.8+ | Core ML pipeline, preprocessing, and model training |
| NLP Features | TF-IDF Vectorizer (scikit-learn) | Convert news text into numerical feature vectors |
| Model 1 | Logistic Regression (scikit-learn) | Fast, lightweight binary classification baseline |
| Model 2 | Linear SVM (scikit-learn) | Higher accuracy on large noisy text feature spaces |
| Model 3 | DistilBERT (HuggingFace Transformers) | Transformer-based deep learning for contextual understanding |
| Deep Learning | PyTorch (torch) | Backend engine for running the DistilBERT model |
| Web Interface | Streamlit | Deploy and interact with the ML model via a browser |
| Data | pandas + numpy | Dataset loading, preprocessing, and manipulation |
How the Three Models Work
Model 1 — TF-IDF + Logistic Regression
Text is converted into a TF-IDF matrix where each word gets a score based on how often it appears in one article versus all articles. Logistic Regression then performs binary classification — REAL or FAKE — on these scores. It is fast, lightweight, and easy to explain in viva. This is the best baseline model for students just starting with NLP.
Model 2 — TF-IDF + Linear SVM
The same TF-IDF features are passed to a Linear Support Vector Machine, which finds the optimal hyperplane to separate fake and real news in high-dimensional feature space. SVM handles noisy, high-dimensional text data better than Logistic Regression and delivers noticeably higher accuracy on the news dataset.
Model 3 — DistilBERT (Deep Learning)
DistilBERT is a lighter, faster version of Google’s BERT transformer model. Unlike TF-IDF, it understands the actual meaning and context of words — not just their frequency. It captures sentence structure, tone, and language patterns that TF-IDF misses. This gives the highest accuracy of all three models and makes this project perfect for students who want to explore Deep Learning and transformer architecture.
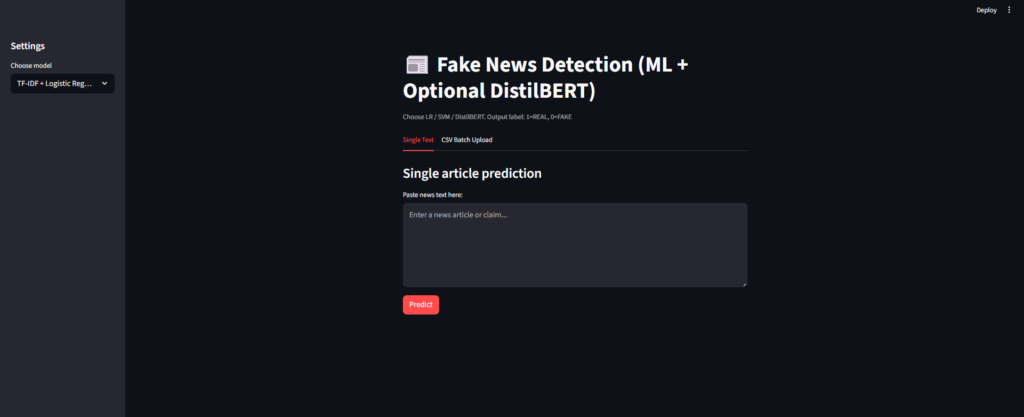
How It Works
Single article prediction flow
- User opens the Streamlit web interface in the browser at
http://localhost:8501 - User pastes a news article into the text input box and selects the model (LR, SVM, or BERT)
- The text is cleaned — stopwords removed, lowercased, punctuation stripped
- For LR and SVM, the cleaned text is vectorized using the saved TF-IDF transformer; for BERT, it is tokenized using the DistilBERT tokenizer
- The selected model runs the prediction and returns REAL or FAKE with a confidence percentage displayed on screen
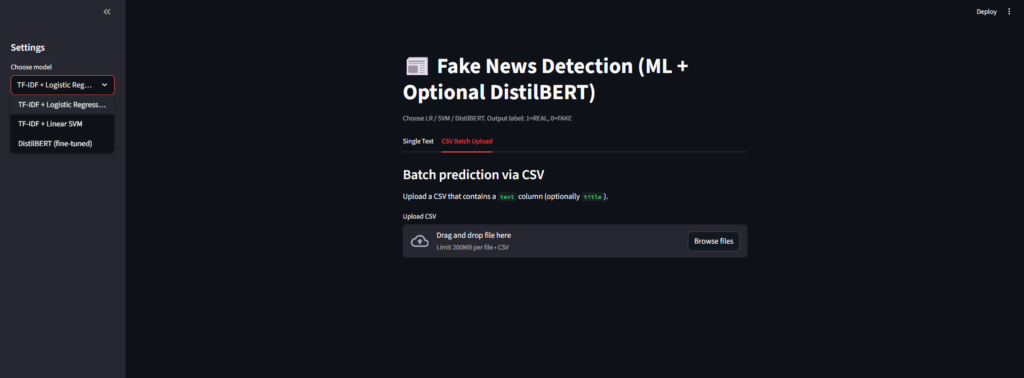
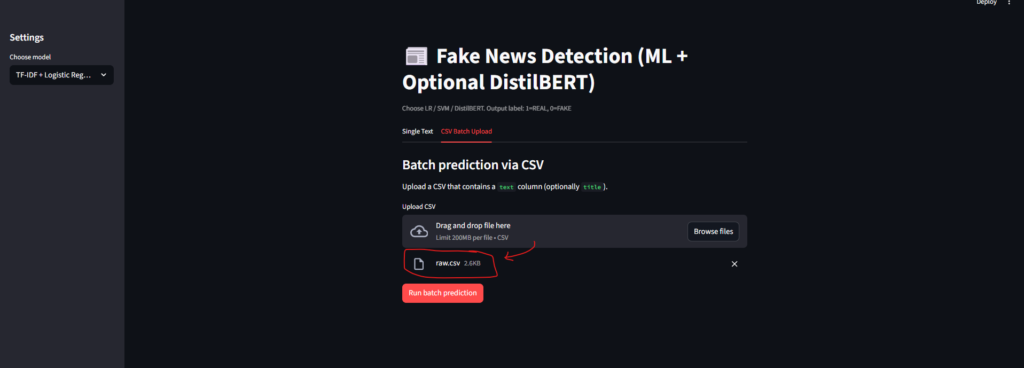
Batch CSV prediction flow
- User uploads a CSV file containing a column of news article texts
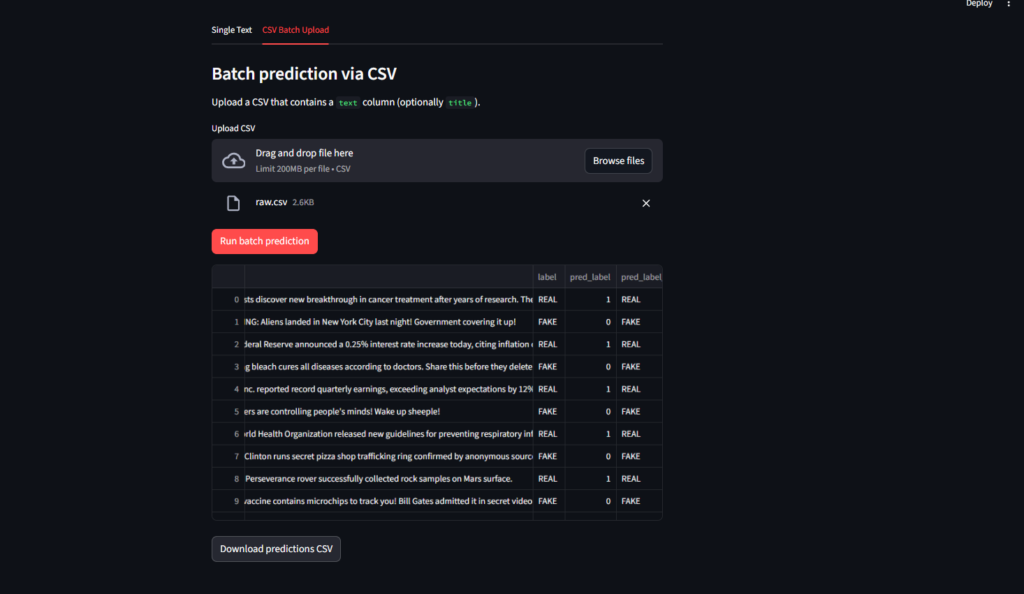
- The app reads each row, preprocesses the text, and runs the selected model on every article
- Results are shown in a table — article text, predicted label (REAL/FAKE), and confidence score for each row
- User clicks Download Results to export the prediction table as a CSV file for project documentation
Model training pipeline
- Raw dataset of labelled real and fake news articles is loaded using pandas
- Text is preprocessed — tokenized, stopwords removed, TF-IDF vectorizer fitted on the training split
- Logistic Regression and SVM are trained on TF-IDF features using scikit-learn’s
fit()method - DistilBERT is fine-tuned on the same labelled dataset using HuggingFace Transformers and PyTorch
- All three trained models and the TF-IDF vectorizer are saved to disk using
pickle/joblibfor loading at inference time
How to Run This Project
Step 1 — Enter the project folder
cd fake-news-detection Step 2 — Create a virtual environment (recommended)
# Windows
python -m venv venv
venv\Scripts\activate
# macOS / Linux
python -m venv venv
source venv/bin/activateStep 3 — Install all dependencies
pip install -r requirements.txtThe requirements.txt includes all packages needed:
pandas
numpy
scikit-learn
transformers
torch
streamlitStep 4 — Train the models (first-time only)
python train.pyThis trains all three models on the dataset and saves the trained files to the models/ folder.
Step 5 — Launch the Streamlit app
streamlit run app.pyOpen http://localhost:8501 in your browser. Paste any news article and get a REAL or FAKE prediction instantly.
Download Full Source Code
Get the complete project with full source code, dataset, trained model files, and setup guide. Remote support is available if you face any issues during installation or deployment.
Future Scope and Improvements
- Multi-language detection — extend the model beyond English to detect fake news in Hindi, Spanish, or other languages
- Image and video analysis — detect fake news embedded in media content using computer vision
- Source credibility scoring — rank news sources by historical reliability and flag low-trust domains
- Browser extension — detect fake news in real time as users browse news websites
- AI-generated content detection — flag articles written by ChatGPT or other generative AI tools
- Research paper scope — the three-model comparison makes this project suitable for publishing in college journals or IEEE conferences
Why This is a Great Final Year Project
- Three ML models in one codebase — Logistic Regression, SVM, and DistilBERT together make this project stand out from every single-model submission in your class
- NLP fundamentals fully covered — tokenization, stopword removal, TF-IDF vectorization, and transformer tokenization are all demonstrated in real working code
- Streamlit deployment is a highly demanded, industry-relevant skill that most students never learn — this project teaches it from scratch
- BERT and transformer architecture shows examiners you understand modern deep learning, not just classical ML algorithms
- Real-world problem — fake news detection is actively researched by companies like Google, Meta, and Twitter; building it as a student project directly connects to what the industry needs
- Batch CSV analysis and downloadable results make the project feel like a complete product, not just a notebook
- Strong resume value — Python + NLP + Transformers + Streamlit deployment is a data science and AI skill set that companies actively hire for
You Might Also Like:
- Heart Disease Risk Prediction using Python and Machine Learning
- UPI Fraud Detection System using Python Flask and ML
- Object Detection Project in Python — Free Source Code
- Car Price Prediction System using Machine Learning
- AI Chatbot Using Python — Full Project with Source Code
- All Machine Learning Projects with Source Code — UpdateGadh
- KEYWORDS:
- Fake News Detection System india
- Fake News Detection System kaggle
- Fake News Detection System dataset
- Fake News Detection System app
- Fake News Detection System geeksforgeeks
- fake news detection dataset kaggle
- fake news detection dataset india
- fake news detection project ppt
- fake news detection system project
- fake news detection system project pdf
- fake news detection system github
- fake news detection system python
- fake news detection system pdf
- fake news detection using machine learning
- fake news detection website
- fake news detection system in machine learning
🎓 Need Complete Final Year Project?
Get Source Code + Report + PPT + Viva Questions (Instant Access)
🛒 Visit UpdateGadh Store →