
Fake Review Detection System using NLP and ML
Introduction
These days, when people shop online, product reviews really help them decide what to buy. But some reviews are fake — either to make a product look better or to harm others.To solve this problem, we made a Fake Review Detection System using NLP and Machine Learning. It comes with an easy-to-use web app made with Streamlit.Users can upload a CSV file with product reviews, and the system will check them. Then, it gives two download files — one with real reviews and one with fake ones.
What You Will Learn
- How to preprocess review data
- How to train an NLP-based ML model
- How to classify fake vs. real reviews
- How to create a web interface using Streamlit
- How to handle file upload and download in a web app
Heart Attack Prediction Using Machine Learning : Click here
Tech Stack
- Frontend: Streamlit (Python-based web framework)
- Backend: Logistic Regression with TF-IDF Vectorizer
- Language: Python
- Libraries: Pandas, NumPy, scikit-learn, re, string
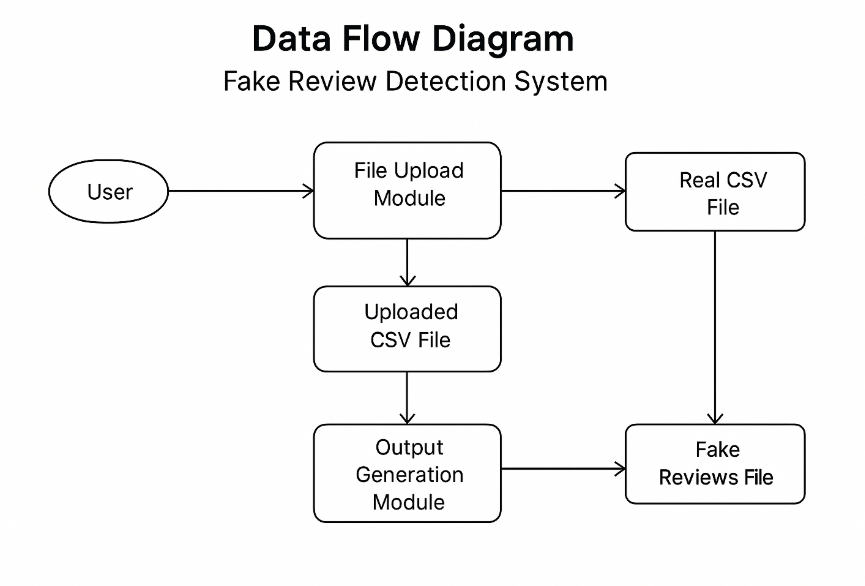
Streamlit App Flow
1. Upload the CSV file
Users upload a CSV containing product review data.
2. NLP Model Processes Reviews
The system preprocesses the text (lowercasing, punctuation and digit removal) and uses a pre-trained TF-IDF + Logistic Regression model to classify reviews.
3. Download the Results
Two downloadable CSVs are generated: real_reviews.csv and fake_reviews.csv.
New Real World Projects : Click Here
Required CSV Format
Ensure your file follows this structure:
| category | rating | label | text_ |
|---|---|---|---|
| Home_and_Kitchen_5 | 5 | CG | Love this! Well made, sturdy. |
| Home_and_Kitchen_5 | 1 | OR | Missing information on how to use it. |
category: Product categoryrating: Star rating (1-5)label: CG for genuine, OR for othertext_: The review content
How Fake/Real Is Determined
We used TF-IDF (Term Frequency-Inverse Document Frequency) to transform text data into numerical vectors. Then, we trained a Logistic Regression model using labeled data:
- Label
CGis treated as real (1) - Others are treated as fake (0)
Full Streamlit Code Overview
The app is a single Python file:
- Loads and trains a model using a sample dataset
- Allows CSV upload
- Validates column structure
- Preprocesses text
- Classifies reviews
- Generates download buttons for real and fake reviews
How to Run the App
- Save the app as
fake_review_app.py - Install dependencies:
pip install streamlit pandas numpy scikit-learn- Run the Streamlit app:
streamlit run fake_review_app.py- Open your browser at
http://localhost:8501 - Upload your review CSV and download results!
Report Structure
✅ Abstract
Short summary of the project (100–200 words).
Should include objective, methodology (ML/Deep Learning/Tools), and key results.
✅ Introduction
Overview: General context (e.g., healthcare, environment, salary prediction, etc.).
Problem Statement: The main issue being solved.
Motivation: Why this project is important and useful.
✅ Literature Review
Previous works, research papers, or existing studies in the same area.
Comparisons of different approaches.
Gaps in existing research that your project addresses.
✅ Existing System & Drawbacks
How current systems/methods work.
Their limitations (accuracy, scalability, cost, user experience, etc.).
✅ Proposed System
Description of your solution.
Features, advantages, and innovations over existing system.
✅ System Architecture (Diagrams)
High-level architecture diagram.
Data flow diagram (DFD).
Use-case diagram (if needed).
✅ System Specifications
Hardware Requirements: CPU, RAM, GPU, Storage.
Software Requirements: OS, Python, Libraries, Frameworks, Database.
✅ Experimental Design Diagrams
Workflow diagrams showing data preprocessing, training, testing, and prediction pipeline.
Flowchart/ER diagram (if using database).
✅ Implementation
Setup process (environment installation).
Explanation of modules.
Sample code snippets with explanation.
✅ System Testing
Types of testing done (Unit, Integration, System, User testing).
Test cases and results.
✅ Results & Screenshots
Output graphs, charts, prediction results.
Screenshots of web/app interface.
✅ Conclusion & Future Scope
Summary of achievements.
Limitations of the project.
Future improvements (adding more features, real-time deployment, cloud integration).
✅ References
Research papers, articles, official documentation, datasets.
Follow IEEE or APA referencing style.

🎓 Need Complete Final Year Project?
Get Source Code + Report + PPT + Viva Questions (Instant Access)
🛒 Visit UpdateGadh Store →